

Mit Text-to-Speech-Software (TTS) können Websites und RSS-Feeds vertont und Podcast-Files in Echtzeit erstellt werden. Im zweiten Teil werden Fragen der Technik und Schnittpunkte zu CMS skizziert.
Folgende technische Faktoren sind bei serverseitiger TTS-Software zu beachten.
– Verbindungsgeschwindigkeit des Clients
– Speicherformat für Text-Strings
Bei TTS und Contentmanagement sind zusätzlich folgende Fragen zu durchdenken:
– Welche Worte sollte man bei der Erstellung von Texten verwenden?
– Wie kann die Aussprache von Texten gesteuert werden?
Schließlich kann man TTS auch für Lerninhalte und zur Effizienzierung crossmedialer Angebote nutzen.
I. Technische Grundfragen von Text-to-Speech-Software
1. Verbindungsgeschwindigkeit
Grundsätzlich sind MP3-Files streamfähig. Die zu transportierende Datenmenge schwankt aber erheblich je nach Soundqualität (fps/kbps). 56k-Verbindungen können zwar theoretisch verwendet werden, aber das Ergebnis ist nicht immer überzeugend. Die zunehmende DSL-Verbreitung lässt die Frage aber nicht mehr so wichtig erscheinen wie noch vor wenigen Jahren.
Richtwerte für Sound bei einer DSL-Verbindung:
![]()
Unabhängig von der Verbindungsgeschwindigkeit spielt die Erstellungsgeschwindigkeit eine große Rolle: Für das Erstellen von MP3s aus langen Texten (z.B. > 5.000 Zeichen) benötigt der TTS-Server einige Zeit. Je nach Serverbelastung können dabei Wartezeiten entstehen.
Eine Lösung: Verwendet man zur Wiedergabe Adobe Flash, können unter Verwendung des LoadVars-Objekts lange Texte satzweise unterteilt und in eine Vielzahl kleiner Textstrings bzw. MP3-Files umgewandelt werden. Anschließend werden die Files nacheinander abgespielt.
Durch die Aufteilung eine einzelne Files wird der Gesamtprozess von der Umwandlung bis zum Vorlesen des ersten Satzes erheblich verkürzt.
Bild: Aufteilung von langem Text in Einzelteile
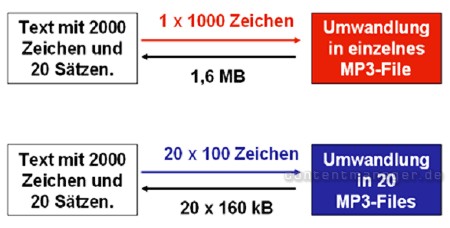
Die Aufteilung in einzelne Files hat verschiedene Vorteile. Allerdings empfiehlt sich dafür die Verwendung von Adobe Flash als MP3-Player.
Durch die satzweise Aufteilung kann zudem jeder vorgelesene Satz zur Laufzeit farblich markiert werden. Der User kann dadurch z.B. erkennen, wo sich der gesprochene Text gerade befindet. Besonders bei längeren Texten kann der User damit abschätzen, wie viel Text noch zu lesen ist. Auch das selektive Vorlesen markierter Textteile ist so grundsätzlich machbar.
2. Speicherformat von TTS
Jeder gesendete String muss von Formatierungszeichen befreit werden – diese werden sonst vorgelesen. Ein entsprechender Parser kann sowohl client- als auch serverseitig integriert werden. Bei RSS-Feeds ist dies nur dann ein Problem, wenn die Inhalte des Feeds CDATA-Formatierungen enthalten.
Folgende Varianten sind häufig:
Variante 1: Ohne Parser
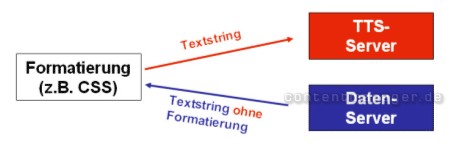
Für diese Variante müssen die Textinhalte vollkommen getrennt von den Formatierungen ausgeliefert werden (z.B. unformatiertes XML oder Nutzung von Variablen).
Variante 2: Clientseitiger Parser
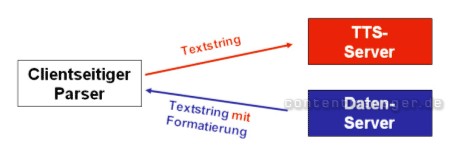
Diese Variante bietet sich z.B. bei CDATA-Formatierungen und der Verwendung von Adobe Flash an: Im PlugIn ist bereits ein Parser enthalten.
Variante 3: Serverseitiger Parser
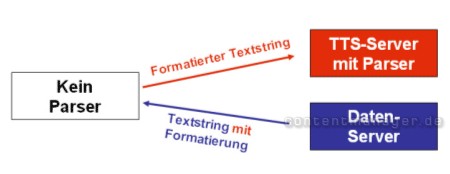
Entweder befindet sich der Parser auf dem TTS-Server oder auf dem Datenserver des Anbieters (dann vorherige Umwandlung per Request, z.B. über AJAX notw.).
Daneben gibt es Mischformen. Jede der skizzierten Varianten hat Vor- und Nachteile. Es kommt daher auf das konkrete Einsatzszenario an. Die skizzierte Problematik bildet zugleich die Schnittstelle zum Contentmanagement, da im CMS die Ausgabeformate für TTS definiert werden müssen:
– unformatiertes XML (RSS)
– CDATA-formatiertes XML (RSS)
– Fertiges HTML
– Unformatierte Texte als Variablen z.B. in JS- oder Textfiles
– usw.
Da existierende Websites bereits die eine oder andere Variante verwenden, wird sich die letztendliche Lösung an dem Ist-Stand einer Website orientieren.
II. Contentmanagement – Bisherige Einflussmöglichkeiten
Bislang dürften nur die wenigsten Contentmanagementsysteme auf die Verarbeitung von TTS eingestellt sein. Künftig könnte sich hier aber ein interessantes Arbeitsfeld ergeben: Zum Beispiel werden Redakteure die Aussprache einzelner Worte in absehbarer Zukunft selbst steuern können.
1. Bisherige Einflussmöglichkeiten
Nahezu alle aktuellen TTS-Produkte haben Probleme mit einzelnen Worten oder Wortfolgen. Das gilt neben mehrdeutigen Begriffen wie „BAND“ (= englische Band oder deutsches Band) auch für Eigenbegriffe oder Firmennamen (z.B. N24 oder SAP).
Für die Ersteller der TTS-Lösungen ist die Anzahl derartiger Begriffe kaum überschaubar – abgesehen von der Klärung der Frage, wie die Worte nun richtig ausgesprochen werden: Als Einzelbuchstaben oder als Buchstabenfolge. Abkürzungen können die gleichen Probleme verursachen.
Redakteure, die wissen, dass ihre Texte nicht nur gelesen, sondern auch häufig gehört werden, sollten daher möglichst im CMS einen Probedurchlauf machen: So können sie die entsprechenden Klippen identifizieren und durch Hinzufügen z.B. von bestimmten oder unbestimmten Artikeln entschärfen. Auch die Umstellung oder der Austausch von Worten kann sich empfehlen.
Als Goody für den diesbezüglichen Mehraufwand erhält der Redakteur einen Service: Mit TTS lassen sich viele Rechtschreibfehler (insbesondere Buchstabendreher) leichter als mit Lesen identifizieren.
Ein Faktor der Rechtschreibprüfung: Das Gehirn vervollständigt automatisch Worte und Sätze – mit TTS werden die Dreher sofort akustisch entlarvt.
The phaonmneal pweor of the hmuan mnid, aoccdrnig to a rscheearch at Cmabrigde Uinervtisy, it deosn’t mttaer in waht oredr the ltteers in a wrod are, the olny iprmoatnt tihng is taht the frist and lsat ltteer be in the rghit pclae.
Bild: Verifizierung von Aussprache direkt im CMS

Im CMS COMMANDA ist ein TTS-Modul enthalten, mit dem der Redakteur alle Texte vorab akustisch überprüfen kann.
Neben den bereits genannten Möglichkeiten haben Redakteure je nach TTS-Hersteller die Möglichkeit, mit sprachergänzenden Elementen die Authentizität der Sprache zu erhöhen. Beispielsweise können Laute wie „Lachen“, „Husten“ oder „Schlucken“ zugefügt werden ( actor.loquendo.com ). Entsprechende Inhalte sind z.B. über Backslash-kommentierte Begriffe definierbar.
Damit der Redakteur die Übersicht über entsprechende Möglichkeiten behält, wird es notwendig sein, z.B. vordefinierte Pulldownmenus direkt in ein CMS zu integrieren, die eine Übersicht über entsprechende Steuerungsmöglichkeiten ermöglichen.
2. Einflussmöglichkeiten in Zukunft von Text to Speech Software (TTS)
a) Regelung von Aussprache und Betonung
Bei führenden TTS-Schmieden bereits in Vorbereitung sind Tools, mit denen der Redakteur die Aussprache bestimmter Worte auf dem TTS-Server selbst definiert. So kann insbesondere die Aussprache von Eigenbegriffen oder Fremdworten reguliert werden. Gleiches gilt für die Betonung (= fragend oder behauptend) bzw. die Lautstärke (flüsternd oder schreiend). Entsprechende Inhalte könnten ebenfalls über Backslash-Kommentierung direkt in den Text eingefügt werden.
Bild: Pflege von Aussprache und Betonung durch Redakteur
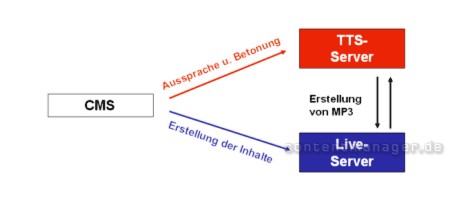
Künftig werden Redakteure die Aussprache und Betonung von Worten selbst regulieren können. Entsprechende Interfaces könnten sogar direkt in ein CMS integriert werden.
Diese Erweiterung wird vor allem dann Sinn machen, wenn TTS-Server ähnlich wie wikipedia.de von vielen Usern gleichzeitig inhaltlich geprägt werden. Eine entsprechende „TTS- Community“ würde effizienter und konsequenter als jeder Softwarehersteller dafür sorgen, dass in denkbar kurzer Zeit möglichst viele Begriffe optimal ausgesprochen werden.
b) Verwendung eigener Sprecher
Angeblich bevorzugen 9 von 10 Menschen TTS-Frauenstimmen ( www.readspeaker.de ), daher stellt sich die Frage nach der richtigen Sprecherwahl und der akustischen Differenzierung von TTS-Angeboten.
Eine interessante Option ist die Verwendung von eigenen Sprechern z.B. von der Tagesschau oder vom Heute-Journal. Claus Kleber als TTS-Sprecher würde die Authentizität von entsprechenden News beim ZDF vermutlich ebenso erhöhen wie die Stimme von Peter Kloeppel auf RTL.
Zusammen mit der zuvor skizzierten Möglichkeit der Aussprache-Steuerung hätten die Online-Redakteure z.B. die Möglichkeit verschiedene Sprecher für ihre Contents zu wählen (z.B. Nachrichtensprecher für News und Promies für Sport oder Unterhaltung).
Die Kombination wäre eine gute Basis für die automatisierte Erstellung von TTS-Podcasting-Angeboten mit hoher Qualität.
Wann allerdings tatsächlich mit entsprechenden Angeboten zu rechnen sein wird, ist fraglich: Technisch ist die Sache zwar weniger problematisch, aber sie ist aktuell noch zeitaufwändig und nicht unbedingt preiswert.
c) Computer-Based-Training / Helpdesk-Anwendungen
Ein Bereich, der die TTS-Nachfrage durchaus beflügeln könnte, ist Computer-Based-Training (CBT). Hier ist das ROI vergleichsweise einfach zu berechnen.
Wie entsprechende TTS-Angebote der Zukunft aussehen könnten, zeigt ein Beispiel mit traditionellem Sprechertext von Mercedes . Entsprechende Angebote sind auch Userseitig begehrt, weil sie die Nutzung besser verdeutlichen wie schlichter Text.
Bild: Interaktive Bedienungsanleitung mit klassischem Sprechertext
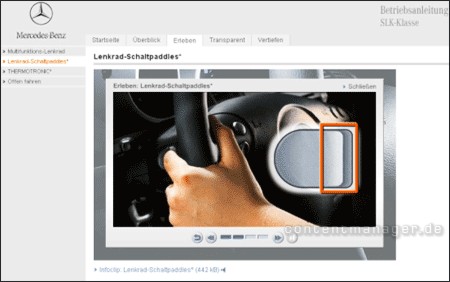
Interaktive Bedienungsanleitungen wie diese können künftig direkt in einem entsprechenden CMS erstellt werden: Durch TTS lassen sich Schrifttext, Bild, Animation und sogar Videos unproblematisch synchronisieren und/oder in mehreren Sprachen erstellen und warten.
Interaktive Bedienungsanleitungen mit klassischem Sprechertext sind zudem kostenintensiv und im Hinblick auf Inhaltsänderungen und Mehrsprachversionen nur bedingt flexibel: Jede Änderung zieht weiterere Prozesse hinter sich her (neue Soundfiles Erstellen & neue Einbindung). Entsprechende Angebote leisten sich daher fast ausnahmslos Großkonzerne.
Die Kosten für entsprechende Angebote würden mit TTS sowohl bei der Erstellung als auch der Pflege deutlich reduziert. Zudem lassen sich Mehrsprachversionen direkt über die Textfunktionen eines CMS mit Bildern und Audio oder Video synchronisieren. Ein gerade für den Mittelstand interessantes TTS-Szenario.
Bild: Synchronisierung von Animation und Text direkt im CMS

Die Erstellung von animierten Inhalten kann direkt im CMS COMMANDA erfolgen und mit TTS synchronisiert werden. Notwendig sind dafür CDATA formatierte RSS-Feeds, die Animationsinformationen über Tags satzgenau zuordnen können.
Bild: Wiedergabe von synchronisierter Animation und TTS
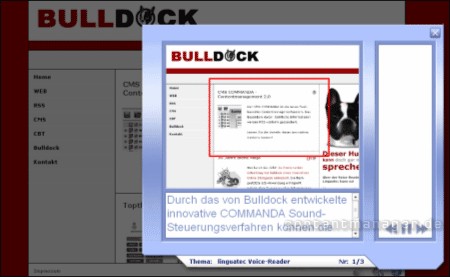
Synchronisation von Bild, Grafik und Text: Grundsätzlich lassen sich mit der gleichen Technologie auch Flash-Videos über ein CMS mit Text synchronisieren und vertonen – in verschiedenen Sprachen.
Entsprechende CBT-Lösungen könnten aus mehreren Gründen die Akzeptanz von TTS beflügeln:
Vorteile für Nutzer:
- Sprache erhöht die Merkfähigkeit deutlich.
- Lerndialoge mit mehreren Sprechern (abwechselnd Frau und Mann) machen TTS angenehmer und reduzieren die Monotonität.
- Durch die Konzentration auf die Bildinhalte tritt die Sprachqualität etwas in den Hintergrund.
Vorteile für Ersteller:
- Mit einem flashbasierten CMS und RSS können Helpdesk-Inhalte einfach erstellt, animiert und mehrsprachig gepflegt werden.
- Neben der Synchronisation von Text und Bild können sogar Videos exakt kommentiert und mit Grafiken (z.B. Pfeilen oder Kreisen) ergänzt werden.
- Crossmedialer Output der Inhalte ist mit ein und dem gleichen CMS möglich (Print, statisches Web, animierte Wiedergabe).
Bild: Sound erhöht nachweislich die Lerneffizienz

Dank moderner CMS stellt die Thematik zugleich eine Brücke zum Crossmedia-Publishing dar. Quasi tagesaktuell können per CMS z.B. Blended-Learning-Inhalte (= kombiniertes eLearning und Training) aufeinander abgestimmt werden.
Bild: Crossmediale Inhalteverwaltung mittels CMS und TTS
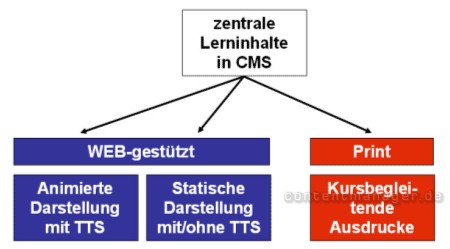
Ein und die gleichen Daten können über ein CMS in Echtzeit crossmedial angeglichen und verwendet werden. Grundlage ist in allen drei Fällen der gleiche geschriebene Text.
III. Ausblick
TTS-Software steht gerade erst am Anfang einer möglicherweise rasant verlaufenden Entwicklung, die früher oder später auch das Contentmanagement beeinflussen wird.
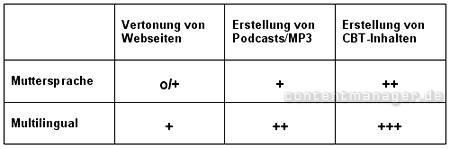
In einer Gesamtbetrachtung aller Faktoren könnte man die möglichen TTS-Einsatzgebiete auf Basis der aktuellen Lösungen folgendermaßen bewerten:
Übersicht: Attraktivität von TTS für unterschiedliche Online-Anwendungen
 Hier gehts zum ersten Teil unseres Beitrags zur Sprachsoftware
Hier gehts zum ersten Teil unseres Beitrags zur Sprachsoftware
Zurück zu Contentmanager.de
Bildquellen
- magnifying-glass-626174_640: Pixabay




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
No Comment